应用层跟踪库¶
概述¶
为了分析应用程序的行为,IDF 提供了一个有用的功能:应用层跟踪。这个功能以库的形式提供,可以通过 menuconfig 开启。此功能使得用户可以在程序运行开销很小的前提下,通过 JTAG 接口在主机和 ESP32 之间传输任意数据。
开发人员可以使用这个功能库将应用程序的运行状态发送给主机,在运行时接收来自主机的命令或者其他类型的信息。该库的主要使用场景有:
收集应用程序特定的数据,具体请参阅 特定应用程序的跟踪
记录到主机的轻量级日志,具体请参阅 记录日志到主机
系统行为分析,具体请参阅 基于 SEGGER SystemView 的系统行为分析
源代码覆盖率,具体请参阅 Gcov(源代码覆盖)
使用 JTAG 接口的跟踪组件工作示意图:
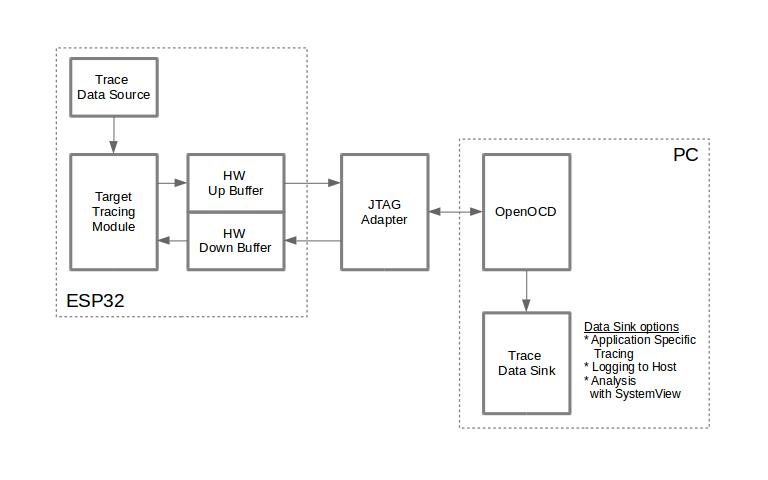
使用 JTAG 接口的跟踪组件¶
运行模式¶
该库支持两种操作模式:
后验模式: 这是默认的模式,该模式不需要和主机进行交互。在这种模式下,跟踪模块不会检查主机是否已经从 HW UP BUFFER 缓冲区读走所有数据,而是直接使用新数据覆盖旧数据。该模式在用户仅对最新的跟踪数据感兴趣时会很有用,例如分析程序在崩溃之前的行为。主机可以稍后根据用户的请求来读取数据,例如通过特殊的 OpenOCD 命令(假如使用了 JTAG 接口)。
流模式: 当主机连接到 ESP32 时,跟踪模块会进入此模式。在这种模式下,跟踪模块在新数据写入 HW UP BUFFER 之前会检查其中是否有足够的空间,并在必要的时候等待主机读取数据并释放足够的内存。用户会将最长的等待时间作为超时时间参数传递给相应的 API 函数,如果超时时间是个有限值,那么应用程序有可能会因为超时而将待写的数据丢弃。尤其需要注意,如果在讲究时效的代码中(如中断处理函数,操作系统调度等)指定了无限的超时时间,那么系统会产生故障。为了避免丢失此类关键数据,开发人员可以通过在 menuconfig 中开启 CONFIG_APPTRACE_PENDING_DATA_SIZE_MAX 选项来启用额外的数据缓冲区。此宏还指定了在上述条件下可以缓冲的数据大小,它有助于缓解由于 USB 总线拥塞等原因导致的向主机传输数据间歇性减缓的状况。但是,当跟踪数据流的平均比特率超过硬件接口的能力时,它也无能为力。
配置选项与依赖项¶
使用此功能需要在主机端和目标端做相应的配置:
主机端: 应用程序跟踪是通过 JTAG 来完成的,因此需要在主机上安装并运行 OpenOCD。相关详细信息请参阅 JTAG Debugging。
目标端: 在 menuconfig 中开启应用程序跟踪功能。 Component config > Application Level Tracing 菜单允许选择跟踪数据的传输目标(具体用于传输的硬件接口),选择任一非 None 的目标都会自动开启
CONFIG_APPTRACE_ENABLE这个选项。
注解
为了实现更高的数据速率并降低丢包率,建议优化 JTAG 的时钟频率,使其达到能够稳定运行的最大值。详细信息请参阅 优化 JTAG 的速度。
以下为前述未提及的另外两个 menuconfig 选项:
Threshold for flushing last trace data to host on panic (CONFIG_APPTRACE_POSTMORTEM_FLUSH_THRESH)。由于在 JTAG 上工作的性质,此选项是必选项。在该模式下,跟踪数据以 16 KB 数据块的形式曝露给主机。在后验模式中,当一个块被填充时,它会曝露给主机,而之前的块会变得不可用。换句话说,跟踪数据以 16 KB 的粒度进行覆盖。在发生 panic 的时候,当前输入块的最新数据将会被曝露给主机,主机可以读取它们以进行后续分析。如果系统发生 panic 的时候仍有少量数据还没来得及曝光给主机,那么之前收集的 16 KB 的数据将丢失,主机只能看到非常少的最新的跟踪部分,它可能不足以用来诊断问题所在。此 menuconfig 选项允许避免此类情况,它可以控制在发生 panic 时刷新数据的阈值,例如用户可以确定它需要不少于 512 字节的最新跟踪数据,所以如果在发生 panic 时待处理的数据少于 512 字节,它们不会被刷新,也不会覆盖之前的 16 KB。该选项仅在后验模式和 JTAG 工作时有意义。
Timeout for flushing last trace data to host on panic (CONFIG_APPTRACE_ONPANIC_HOST_FLUSH_TMO)。该选项仅在流模式下才起作用,它控制跟踪模块在发生 panic 时等待主机读取最新数据的最长时间。
如何使用这个库¶
该库提供了用于在主机和 ESP32 之间传输任意数据的 API。当在 menuconfig 中启用时,目标应用程序的跟踪模块会在系统启动时自动初始化,因此用户需要做的就是调用相应的 API 来发送、接收或者刷新数据。
特定应用程序的跟踪¶
通常,用户需要决定在每个方向上待传输数据的类型以及如何解析(处理)这些数据。要想在目标和主机之间传输数据,用户必须要执行以下几个步骤。
在目标端,用户需要实现将跟踪数据写入主机的算法,下面的代码片段展示了如何执行此操作。
#include "esp_app_trace.h" ... char buf[] = "Hello World!"; esp_err_t res = esp_apptrace_write(ESP_APPTRACE_DEST_TRAX, buf, strlen(buf), ESP_APPTRACE_TMO_INFINITE); if (res != ESP_OK) { ESP_LOGE(TAG, "Failed to write data to host!"); return res; }
esp_apptrace_write()函数使用 memcpy 把用户数据复制到内部缓存中。在某些情况下,使用esp_apptrace_buffer_get()和esp_apptrace_buffer_put()函数会更加理想,它们允许开发人员自行分配缓冲区并填充。下面的代码片段展示了如何执行此操作。#include "esp_app_trace.h" ... int number = 10; char *ptr = (char *)esp_apptrace_buffer_get(ESP_APPTRACE_DEST_TRAX, 32, 100/*tmo in us*/); if (ptr == NULL) { ESP_LOGE(TAG, "Failed to get buffer!"); return ESP_FAIL; } sprintf(ptr, "Here is the number %d", number); esp_err_t res = esp_apptrace_buffer_put(ESP_APPTRACE_DEST_TRAX, ptr, 100/*tmo in us*/); if (res != ESP_OK) { /* in case of error host tracing tool (e.g. OpenOCD) will report incomplete user buffer */ ESP_LOGE(TAG, "Failed to put buffer!"); return res; }
另外,根据实际项目的需要,用户可能希望从主机接收数据。下面的代码片段展示了如何执行此操作。
#include "esp_app_trace.h" ... char buf[32]; char down_buf[32]; size_t sz = sizeof(buf); /* config down buffer */ esp_apptrace_down_buffer_config(down_buf, sizeof(down_buf)); /* check for incoming data and read them if any */ esp_err_t res = esp_apptrace_read(ESP_APPTRACE_DEST_TRAX, buf, &sz, 0/*do not wait*/); if (res != ESP_OK) { ESP_LOGE(TAG, "Failed to read data from host!"); return res; } if (sz > 0) { /* we have data, process them */ ... }
esp_apptrace_read()函数使用 memcpy 来把主机端的数据复制到用户缓存区。在某些情况下,使用esp_apptrace_down_buffer_get()和esp_apptrace_down_buffer_put()函数可能更为理想。它们允许开发人员占用一块读缓冲区并就地进行有关处理操作。下面的代码片段展示了如何执行此操作。#include "esp_app_trace.h" ... char down_buf[32]; uint32_t *number; size_t sz = 32; /* config down buffer */ esp_apptrace_down_buffer_config(down_buf, sizeof(down_buf)); char *ptr = (char *)esp_apptrace_down_buffer_get(ESP_APPTRACE_DEST_TRAX, &sz, 100/*tmo in us*/); if (ptr == NULL) { ESP_LOGE(TAG, "Failed to get buffer!"); return ESP_FAIL; } if (sz > 4) { number = (uint32_t *)ptr; printf("Here is the number %d", *number); } else { printf("No data"); } esp_err_t res = esp_apptrace_down_buffer_put(ESP_APPTRACE_DEST_TRAX, ptr, 100/*tmo in us*/); if (res != ESP_OK) { /* in case of error host tracing tool (e.g. OpenOCD) will report incomplete user buffer */ ESP_LOGE(TAG, "Failed to put buffer!"); return res; }
下一步是编译应用程序的镜像并将其下载到目标板上,这一步可以参考文档 构建并烧写。
运行 OpenOCD(参见 JTAG 调试)。
连接到 OpenOCD 的 telnet 服务器,在终端执行如下命令
telnet <oocd_host> 4444。如果在运行 OpenOCD 的同一台机器上打开 telnet 会话,您可以使用localhost替换上面命令中的<oocd_host>。使用特殊的 OpenOCD 命令开始收集待跟踪的命令,此命令将传输跟踪数据并将其重定向到指定的文件或套接字(当前仅支持文件作为跟踪数据目标)。相关命令的说明请参阅 启动调试器 。
最后一步是处理接收到的数据,由于数据格式由用户定义,因此处理阶段超出了本文档的范围。数据处理的范例可以参考位于
$IDF_PATH/tools/esp_app_trace下的 Python 脚本apptrace_proc.py(用于功能测试)和logtrace_proc.py(请参阅 记录日志到主机 章节中的详细信息)。
OpenOCD 应用程序跟踪命令¶
HW UP BUFFER 在用户数据块之间共享,并且会替 API 的调用者(在任务或者中断上下文中)填充分配到的内存。在多线程环境中,正在填充缓冲区的任务/中断可能会被另一个高优先级的任务/中断抢占,有可能发生主机读取还未准备好的用户数据的情况。为了处理这样的情况,跟踪模块在所有用户数据块之前添加一个数据头,其中包含有分配的用户缓冲区的大小(2 字节)和实际写入的数据长度(2 字节),也就是说数据头总共长 4 字节。负责读取跟踪数据的 OpenOCD 命令在读取到不完整的用户数据块时会报错,但是无论如何它都会将整个用户数据块(包括还未填充的区域)的内容放到输出文件中。
下面是 OpenOCD 应用程序跟踪命令的使用说明。
注解
目前,OpenOCD 还不支持将任意用户数据发送到目标的命令。
命令用法:
esp apptrace [start <options>] | [stop] | [status] | [dump <cores_num> <outfile>]
子命令:
start开始跟踪(连续流模式)。
stop停止跟踪。
status获取跟踪状态。
dump转储所有后验模式的数据。
Start 子命令的语法:
start <outfile> [poll_period [trace_size [stop_tmo [wait4halt [skip_size]]]]
outfile用于保存来自两个 CPU 的数据文件的路径,该参数需要具有以下格式:
file://path/to/file。poll_period轮询跟踪数据的周期(单位:毫秒),如果大于 0 则以非阻塞模式运行。默认为 1 毫秒。
trace_size最多要收集的数据量(单位:字节),接收到指定数量的数据后将会停止跟踪。默认情况下是 -1(禁用跟踪大小停止触发器)。
stop_tmo空闲超时(单位:秒),如果指定的时间段内都没有数据就会停止跟踪。默认为 -1(禁用跟踪超时停止触发器)。还可以将其设置为比目标跟踪命令之间的最长暂停值更长的值(可选)。
wait4halt如果设置为 0 则立即开始跟踪,否则命令等待目标停止(复位,打断点等),然后自动恢复它并开始跟踪。默认值为 0。
skip_size开始时要跳过的字节数,默认为 0。
注解
如果 poll_period 为 0,则在跟踪停止之前,OpenOCD 的 telnet 命令将不可用。必须通过复位电路板或者在 OpenOCD 的窗口中(不是 telnet 会话窗口)按下 Ctrl+C。另一种选择是设置 trace_size 并等待,当收集到指定数据量时,跟踪会自动停止。
命令使用示例:
将 2048 个字节的跟踪数据收集到 “trace.log” 文件中,该文件将保存在 “openocd-esp32” 目录中。
esp apptrace start file://trace.log 1 2048 5 0 0
跟踪数据会被检索并以非阻塞的模式保存到文件中,如果收集满 2048 字节的数据或者在 5 秒内都没有新的数据,那么该过程就会停止。
注解
在将数据提供给 OpenOCD 之前,会对其进行缓冲。如果看到 “Data timeout!” 的消息,则目标可能在超时之前没有发送足够的数据给 OpenOCD 来清空缓冲区。增加超时时间或者使用函数
esp_apptrace_flush()以特定间隔刷新数据都可以解决这个问题。在非阻塞模式下无限地检索跟踪数据。
esp apptrace start file://trace.log 1 -1 -1 0 0
对收集数据的大小没有限制,并且没有设置任何超时时间。可以通过在 OpenOCD 的 telnet 会话窗口中发送
esp apptrace stop命令,或者在 OpenOCD 窗口中使用快捷键 Ctrl+C 来停止此过程。检索跟踪数据并无限期保存。
esp apptrace start file://trace.log 0 -1 -1 0 0
在跟踪停止之前,OpenOCD 的 telnet 会话窗口将不可用。要停止跟踪,请在 OpenOCD 的窗口中使用快捷键 Ctrl+C。
等待目标停止,然后恢复目标的操作并开始检索数据。当收集满 2048 字节的数据后就停止:
esp apptrace start file://trace.log 0 2048 -1 1 0
想要复位后立即开始跟踪,请使用 OpenOCD 的
reset halt命令。
记录日志到主机¶
记录日志到主机是 IDF 的一个非常实用的功能:通过应用层跟踪库将日志保存到主机端。某种程度上这也算是一种半主机(semihosting)机制,相较于调用 ESP_LOGx 将待打印的字符串发送到 UART 的日志记录方式,这个功能的优势在于它减少了本地的工作量,而将大部分工作转移到了主机端。
IDF 的日志库会默认使用类 vprintf 的函数将格式化的字符串输出到专用的 UART。一般来说,它涉及到以下几个步骤:
解析格式字符串以获取每个参数的类型。
根据其类型,将每个参数都转换为字符串。
格式字符串与转换后的参数一起发送到 UART。
虽然可以将类 vprintf 函数优化到一定程度,但是上述步骤在任何情况下都是必须要执行的,并且每个步骤都会消耗一定的时间(尤其是步骤 3)。所以经常会发生以下这种情况:向程序中添加额外的打印信息以诊断问题,却改变了应用程序的行为,使得问题无法复现。在最差的情况下,程序会无法正常工作,最终导致报错甚至挂起。
解决此类问题的可能方法是使用更高的波特率或者其他更快的接口,并将字符串格式化的工作转移到主机端。
通过应用层跟踪库的 esp_apptrace_vprintf 函数,可以将日志信息发送到主机,该函数不执行格式字符串和参数的完全解析,而仅仅计算传递的参数的数量,并将它们与格式字符串地址一起发送给主机。主机端会通过一个特殊的 Python 脚本来处理并打印接收到的日志数据。
局限¶
目前通过 JTAG 实现记录日志还存在以下几点局限:
不支持使用
ESP_EARLY_LOGx宏进行跟踪。不支持大小超过 4 字节的 printf 参数(例如
double和uint64_t)。仅支持 .rodata 段中的格式字符串和参数。
printf 参数最多 256 个。
如何使用¶
为了使用跟踪模块来记录日志,用户需要执行以下步骤:
在目标端,需要安装特殊的类 vprintf 函数,正如前面提到过的,这个函数是
esp_apptrace_vprintf,它会负责将日志数据发送给主机。示例代码参见 system/app_trace_to_host 。按照 特定应用程序的跟踪 章节中第 2-5 步骤中的说明进行操作。
打印接收到的日志记录,请在终端运行以下命令:
$IDF_PATH/tools/esp_app_trace/logtrace_proc.py /path/to/trace/file /path/to/program/elf/file。
Log Trace Processor 命令选项¶
命令用法:
logtrace_proc.py [-h] [--no-errors] <trace_file> <elf_file>
位置参数(必要):
trace_file日志跟踪文件的路径
elf_file程序 ELF 文件的路径
可选参数:
-h,--help显示此帮助信息并退出
--no-errors,-n不打印错误信息
基于 SEGGER SystemView 的系统行为分析¶
IDF 中另一个基于应用层跟踪库的实用功能是系统级跟踪,它会生成与 SEGGER SystemView 工具 相兼容的跟踪信息。SEGGER SystemView 是一种实时记录和可视化工具,用来分析应用程序运行时的行为。
注解
目前,基于 IDF 的应用程序能够以文件的形式生成与 SystemView 格式兼容的跟踪信息,并可以使用 SystemView 工具软件打开。但是还无法使用该工具控制跟踪的过程。
如何使用¶
若需使用这个功能,需要在 menuconfig 中开启 CONFIG_APPTRACE_SV_ENABLE 选项,具体路径为: Component config > Application Level Tracing > FreeRTOS SystemView Tracing 。在同一个菜单栏下还开启了其他几个选项:
ESP32 timer to use as SystemView timestamp source (CONFIG_APPTRACE_SV_TS_SOURCE)选择 SystemView 事件使用的时间戳来源。在单核模式下,使用 ESP32 内部的循环计数器生成时间戳,其最大的工作频率是 240 MHz(时间戳粒度大约为 4 ns)。在双核模式下,使用工作在 40 MHz 的外部定时器,因此时间戳粒度为 25 ns。
可以单独启用或禁用的 SystemView 事件集合(
CONFIG_APPTRACE_SV_EVT_XXX):Trace Buffer Overflow Event
ISR Enter Event
ISR Exit Event
ISR Exit to Scheduler Event
Task Start Execution Event
Task Stop Execution Event
Task Start Ready State Event
Task Stop Ready State Event
Task Create Event
Task Terminate Event
System Idle Event
Timer Enter Event
Timer Exit Event
IDF 中已经包含了所有用于生成兼容 SystemView 跟踪信息的代码,用户只需配置必要的项目选项(如上所示),然后构建、烧写映像到目标板,接着参照前面的介绍,使用 OpenOCD 收集数据。
OpenOCD SystemView 跟踪命令选项¶
命令用法:
esp sysview [start <options>] | [stop] | [status]
子命令:
start开启跟踪(连续流模式)。
stop停止跟踪。
status获取跟踪状态。
Start 子命令语法:
start <outfile1> [outfile2] [poll_period [trace_size [stop_tmo]]]
outfile1保存 PRO CPU 数据的文件路径,此参数需要具有如下格式:
file://path/to/file。outfile2保存 APP CPU 数据的文件路径,此参数需要具有如下格式:
file://path/to/file。poll_period跟踪数据的轮询周期(单位:毫秒)。如果该值大于 0,则命令以非阻塞的模式运行。默认为 1 毫秒。
trace_size最多要收集的数据量(单位:字节)。当收到指定数量的数据后,将停止跟踪。默认值是 -1 (禁用跟踪大小停止触发器)。
stop_tmo空闲超时(单位:秒)。如果指定的时间内没有数据,将停止跟踪。默认值是 -1(禁用跟踪超时停止触发器)。
注解
如果 poll_period 为 0,则在跟踪停止之前,OpenOCD 的 telnet 命令行将不可用。你需要通过复位板卡或者在 OpenOCD 的窗口(不是 telnet 会话窗口)输入 Ctrl+C 命令来手动停止它。另一个办法是设置 trace_size 然后等到收集满指定数量的数据后自动停止跟踪。
命令使用示例:
将 SystemView 跟踪数据收集到文件 “pro-cpu.SVDat” 和 “pro-cpu.SVDat” 中。这些文件会被保存在 “openocd-esp32” 目录中。
esp sysview start file://pro-cpu.SVDat file://app-cpu.SVDat
跟踪数据被检索并以非阻塞的方式保存,要停止此过程,需要在 OpenOCD 的 telnet 会话窗口输入
esp sysview stop命令,或者也可以在 OpenOCD 窗口中按下 Ctrl+C。检索跟踪数据并无限保存。
esp32 sysview start file://pro-cpu.SVDat file://app-cpu.SVDat 0 -1 -1
OpenOCD 的 telnet 命令行在跟踪停止前会无法使用,要停止跟踪,请在 OpenOCD 窗口按下 Ctrl+C。
数据可视化¶
收集到跟踪数据后,用户可以使用特殊的工具来可视化结果并分析程序的行为。
遗憾的是,SystemView 不支持从多个核心进行跟踪。所以当追踪双核模式下的 ESP32 时会生成两个文件:一个用于 PRO CPU,另一个用于 APP CPU。用户可以将每个文件加载到工具中单独分析。
在工具中单独分析每个核的跟踪数据是比较棘手的,但是 Eclipse 提供了一个叫 Impulse 的插件可以加载多个跟踪文件,并且可以在同一个视图中检查来自两个内核的事件。此外,与免费版的 SystemView 相比,此插件没有 1,000,000 个事件的限制。
关于如何安装、配置 Impulse 并使用它可视化来自单个核心的跟踪数据,请参阅 官方教程 。
注解
IDF 使用自己的 SystemView FreeRTOS 事件 ID 映射,因此用户需要将 $SYSVIEW_INSTALL_DIR/Description/SYSVIEW_FreeRTOS.txt 替换成 $IDF_PATH/docs/api-guides/SYSVIEW_FreeRTOS.txt。
在使用上述链接配置 SystemView 序列化程序时,也应该使用该 IDF 特定文件的内容。
配置 Impulse 实现双核跟踪¶
在安装好 Impulse 插件并确保 Impulse 能够在单独的选项卡中成功加载每个核心的跟踪文件后,用户可以添加特殊的 Multi Adapter 端口并将这两个文件加载到一个视图中。为此,用户需要在 Eclipse 中执行以下操作:
打开 “Signal Ports” 视图,前往 Windows->Show View->Other 菜单,在 Impulse 文件夹中找到 “Signal Ports” 视图,然后双击它。
在 “Signal Ports” 视图中,右键单击 “Ports” 并选择 “Add …”,然后选择 New Multi Adapter Port。
在打开的对话框中按下 “Add” 按钮,选择 “New Pipe/File”。
在打开的对话框中选择 “SystemView Serializer” 并设置 PRO CPU 跟踪文件的路径,按下确定保存设置。
对 APP CPU 的跟踪文件重复步骤 3 和 4。
双击创建的端口,会打开此端口的视图。
单击 Start/Stop Streaming 按钮,数据将会被加载。
使用 “Zoom Out”,“Zoom In” 和 “Zoom Fit” 按钮来查看数据。
有关设置测量光标和其他的功能,请参阅 Impulse 官方文档 。
注解
如果您在可视化方面遇到了问题(未显示数据或者缩放操作异常),您可以尝试删除当前的信号层次结构,再双击必要的文件或端口。Eclipse 会请求您创建新的信号层次结构。
Gcov(源代码覆盖)¶
Gcov 和 Gcovr 简介¶
源代码覆盖率显示程序运行时间内执行的每一条程序执行路径的数量和频率。Gcov 是一个 GCC 工具,与编译器协同使用时,可生成日志文件,显示源文件每行的执行次数。Gcovr 是管理 Gcov 和生成代码覆盖率总结的工具。
一般来说,使用 Gcov 在主机上编译和运行程序会经过以下步骤:
使用 GCC 以及
--coverage选项编译源代码。这会让编译器在编译过程中生成一个.gcno注释文件,该文件包含重建执行路径块图以及将每个块映射到源代码行号等信息。每个用--coverage选项编译的源文件都会有自己的同名.gcno文件(如main.c在编译时会生成main.gcno)。执行程序。在执行过程中,程序会生成
.gcda数据文件。这些数据文件包含了执行路径的次数统计。程序将为每个用--coverage选项编译的源文件生成一个.gcda文件(如main.c将生成main.gcda)。Gcov 或 Gcovr 可用于生成基于
.gcno、.gcda和源文件的代码覆盖。Gcov 将以.gcov文件的形式为每个源文件生成基于文本的覆盖报告,而 Gcovr 将以 HTML 格式生成覆盖报告。
ESP-IDF 中 Gcov 和 Gcovr 应用¶
在 ESP-IDF 中使用 Gcov 比较复杂,因为程序不在主机上运行(即在目标机上运行)。代码覆盖率数据(即 .gcda 文件)最初存储在目标机上。然后 OpenOCD 在运行时通过 JTAG 将代码覆盖数据从目标机转储到主机上。在 ESP-IDF 中使用 Gcov 可以分为以下几个步骤:
为 Gcov 设置项目¶
编译器选项¶
为了获得项目中的代码覆盖率数据,项目中的一个或多个源文件必须用 --coverage 选项进行编译。在 ESP-IDF 中,这可以在组件级或单个源文件级实现:
- 使组件中的所有源文件用
--coverage选项进行编译: 如果使用 CMake,则在组件的
CMakeLists.txt文件中添加target_compile_options(${COMPONENT_LIB} PRIVATE --coverage)。如果使用 Make,则在组件的
component.mk文件中添加CFLAGS += --coverage。
- 使同一组件中选定的一些源文件(如
sourec1.c和source2.c)通过--coverage选项编译: 如果使用 CMake,则在组件的
CMakeLists.txt文件中添加set_source_files_properties(source1.c source2.c PROPERTIES COMPILE_FLAGS --coverage)。如果使用 Make,则在组件的
component.mk文件中添加source1.o: CFLAGS += --coverage和source2.o: CFLAGS += --coverage。
当一个源文件用 --coverage 选项编译时(例如 gcov_example.c),编译器会在项目的构建目录下生成 gcov_example.gcno 文件。
项目配置¶
在构建一个有源代码覆盖的项目之前,请通过运行 idf.py menuconfig``(如使用传统的 Make 构建系统,则启用 ``make menuconfig)启用以下项目配置选项。
通过 CONFIG_APPTRACE_DESTINATION 选项选择 Trace Memory 来启用应用程序跟踪模块。
通过 CONFIG_APPTRACE_GCOV_ENABLE 选项启用 Gcov 主机。
转储代码覆盖数据¶
一旦一个项目使用 --coverage 选项编译并烧录到目标机上,在应用程序运行时,代码覆盖数据将存储在目标机内部(即在跟踪存储器中)。将代码覆盖率数据从目标机转移到主机上的过程称为转储。
覆盖率数据的转储通过 OpenOCD 进行(关于如何设置和运行 OpenOCD,请参考 JTAG调试)。由于是通过向 OpenOCD 发出命令来触发转储,因此必须打开 telnet 会话来向 OpenOCD 发出这些命令(运行 telnet localhost 4444)。GDB 也可以代替 telnet 来向 OpenOCD 发出命令,但是所有从 GDB 发出的命令都需要以 mon <oocd_command> 为前缀。
当目标机转储代码覆盖数据时,.gcda 文件存储在项目的构建目录中。例如,如果 main 组件的 gcov_example_main.c 在编译时使用了 --coverage 选项,那么转储代码覆盖数据将在 build/esp-idf/main/CMakeFiles/__idf_main.dir/gcov_example_main.c.gcda 中(如果使用传统 Make 构建系统,则是在 build/main/gcov_example_main.gcda 中)生成一个 gcov_example_main.gcda 文件。注意,编译过程中产生的 .gcno 文件也放在同一个目录下。
代码覆盖数据的转储可以在应用程序的整个生命周期内多次进行。每次转储都会用最新的代码覆盖信息更新 .gcda 文件。代码覆盖数据是累积的,因此最新的数据将包含应用程序整个生命周期中每个代码路径的总执行次数。
ESP-IDF 支持两种将代码覆盖数据从目标机转储到主机的方法:
运行中实时转储
硬编码转储
运行中实时转储¶
通过 telnet 会话调用 OpenOCD 命令 ESP32 gcov 来触发运行时的实时转储。一旦被调用,OpenOCD 将立即抢占 ESP32 的当前状态,并执行一个内置的 IDF Gcov 调试存根函数。调试存根函数将数据转储到主机。完成后,ESP32 将恢复当前状态。
硬编码转储¶
硬编码转储是由应用程序本身从程序内部调用 esp_gcov_dump() 函数触发的。在调用时,应用程序将停止并等待 OpenOCD 连接并检索代码覆盖数据。一旦 esp_gcov_dump() 函数被调用,主机将通过 telnet 会话执行 esp gcov dump OpenOCD 命令。esp gcov dump 命令会让 OpenOCD 连接到 ESP32,检索代码覆盖数据,然后断开与 ESP32 的连接,从而恢复应用程序。可以在应用程序的生命周期中多次触发硬编码转储。
通过在必要地方放置 esp_gcov_dump() (如在应用程序初始化后,在应用程序主循环的每次迭代期间),当应用程序在生命周期的某刻需要代码覆盖率数据时,硬编码转储会非常有用。
GDB 可以用来在 esp_gcov_dump() 上设置一个断点,然后通过使用 gdbinit 脚本自动调用 mon esp gcov dump (关于 GDB 的使用可参考 使用命令行调试)。
以下 GDB 脚本将在 esp_gcov_dump() 处添加一个断点,然后调用 mon esp gcov dump OpenOCD 命令。
b esp_gcov_dump
commands
mon esp gcov dump
end
注解
注意所有的 OpenOCD 命令都应该在 GDB 中以 mon <oocd_command> 方式调用。
生成代码覆盖报告¶
一旦代码覆盖数据被转储,.gcno、.gcda 和源文件可以用来生成代码覆盖报告。该报告会显示源文件中每行被执行的次数。
Gcov 和 Gcovr 都可以用来生成代码覆盖报告。安装 Xtensa 工具链时会一起安装 Gcov,但 Gcovr 可能需要单独安装。关于如何使用 Gcov 或 Gcovr,请参考 Gcov documentation 和 Gcovr documentation。
在工程中添加 Gcovr 构建目标¶
用户可以在自己的工程中定义额外的构建目标从而更方便地生成报告。可以通过一个简单的构建命令生成这样的报告。
CMake 构建系统¶
对于 CMake 构建系统,请在您工程的 CMakeLists.txt 文件中添加以下内容:
include($ENV{IDF_PATH}/tools/cmake/gcov.cmake)
idf_create_coverage_report(${CMAKE_CURRENT_BINARY_DIR}/coverage_report)
idf_clean_coverage_report(${CMAKE_CURRENT_BINARY_DIR}/coverage_report)
可使用以下命令:
cmake --build build/ --target gcovr-report:在$(BUILD_DIR_BASE)/coverage_report/html目录下生成 HTML 格式代码覆盖报告。
cmake --build build/ --target cov-data-clean:删除所有代码覆盖数据文件。
Make 构建系统¶
对于 Make 构建系统,请在您工程的 Makefile 文件中添加以下内容:
GCOV := $(call dequote,$(CONFIG_SDK_TOOLPREFIX))gcov
REPORT_DIR := $(BUILD_DIR_BASE)/coverage_report
gcovr-report:
echo "Generating coverage report in: $(REPORT_DIR)"
echo "Using gcov: $(GCOV)"
mkdir -p $(REPORT_DIR)/html
cd $(BUILD_DIR_BASE)
gcovr -r $(PROJECT_PATH) --gcov-executable $(GCOV) -s --html-details $(REPORT_DIR)/html/index.html
cov-data-clean:
echo "Remove coverage data files..."
find $(BUILD_DIR_BASE) -name "*.gcda" -exec rm {} +
rm -rf $(REPORT_DIR)
.PHONY: gcovr-report cov-data-clean
可使用以下命令:
make gcovr-report:在$(BUILD_DIR_BASE)/coverage_report/html目录下生成 HTML 格式代码覆盖报告。
make cov-data-clean:删除所有代码覆盖数据文件。