AFE 声学前端算法框架
概述
智能语音设备需要在远场噪声环境中,仍具备出色的语音交互性能,声学前端 (Audio Front-End, AFE) 算法在构建此类语音用户界面 (Voice-User Interface, VUI) 时至关重要。乐鑫 AI 实验室自主研发了一套乐鑫 AFE 算法框架,可基于功能强大的 ESP32-S3 系列芯片进行声学前端处理,使用户获得高质量且稳定的音频数据,从而构建性能卓越且高性价比的智能语音产品。
名称 |
简介 |
|---|---|
AEC (Acoustic Echo Cancellation) |
回声消除算法,最多支持双麦处理,能够有效的去除 mic 输入信号中的自身播放声音,从而可以在自身播放音乐的情况下很好的完成语音识别。 |
NS (Noise Suppression) |
噪声抑制算法,支持单通道处理,能够对单通道音频中的非人声噪声进行抑制,尤其针对稳态噪声,具有很好的抑制效果。 |
BSS (Blind Source Separation) |
盲信号分离算法,支持双通道处理,能够很好的将目标声源和其余干扰音进行盲源分离,从而提取出有用音频信号,保证了后级语音的质量。 |
MISO (Multi Input Single Output) |
多输入单输出算法,支持双通道输入,单通道输出。用于在双麦场景,没有唤醒使能的情况下,选择信噪比高的一路音频输出。 |
VAD (Voice Activity Detection) |
语音活动检测算法,支持实时输出当前帧的语音活动状态。 |
AGC (Automatic Gain Control) |
自动增益控制算法,可以动态调整输出音频的幅值,当弱信号输入时,放大输出幅度;当输入信号达到一定强度时,压缩输出幅度。 |
WakeNet |
基于神经网络的唤醒词模型,专为低功耗嵌入式 MCU 设计 |
使用场景
本节介绍Espressif AFE框架的两种典型应用场景。
语音识别
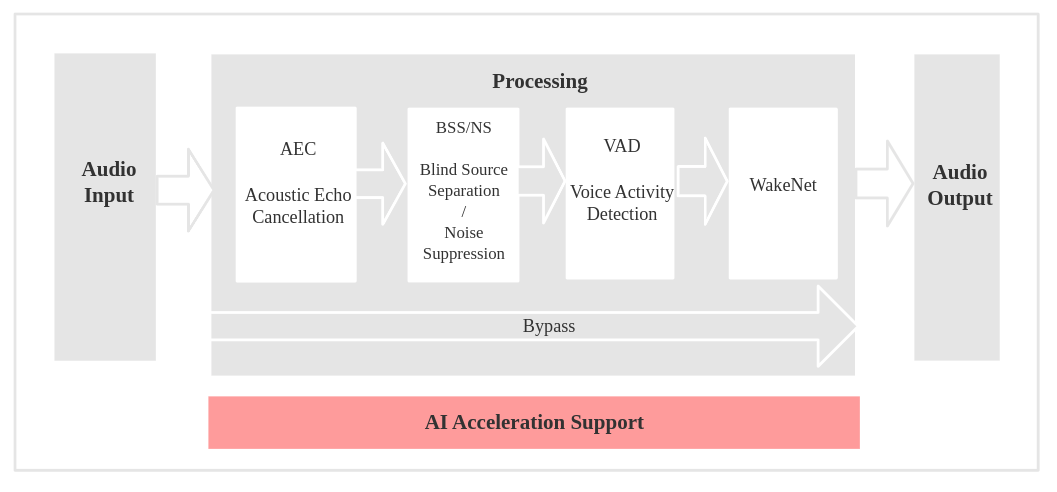
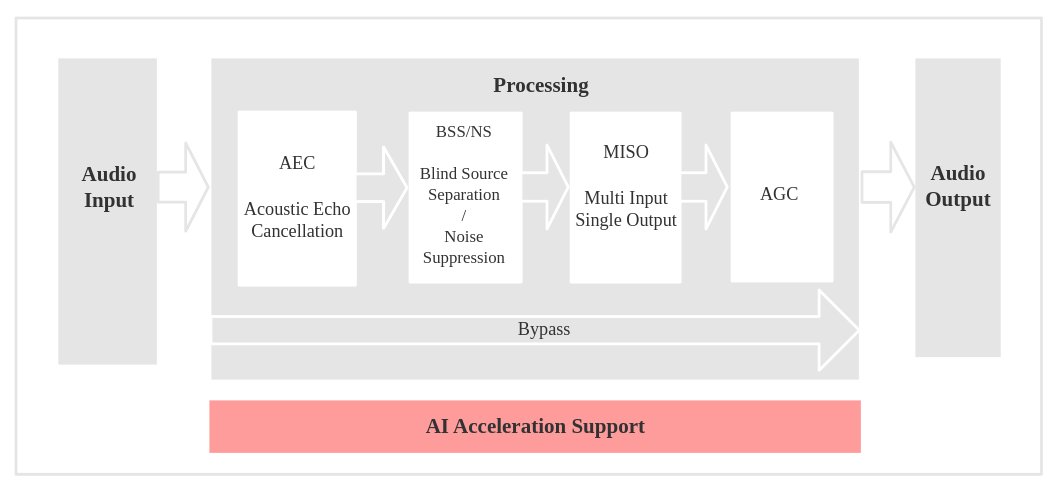
语音通话
输入格式定义
input_format 参数定义了输入数据中音频通道的排列方式。字符串中的每个字符代表一个通道类型:
字符 |
描述 |
|---|---|
|
麦克风通道 |
|
播放参考通道 |
|
未使用或未知通道 |
示例:
"MMNR":表示四通道排列,依次为麦克风通道、麦克风通道、未使用通道和播放参考通道。
备注
输入数据必须采用 通道交错排列格式。
AFE API 使用
根据 menuconfig -> ESP Speech Recognition 选择需要的AFE的模型,比如WakeNet模型,VAD模型, NS模型等,然后在代码中使用以下步骤调用AFE框架。
代码可以参考 test_apps/esp-sr/main/test_afe.cpp 或是 or esp-skainet/examples.。
步骤1:初始化AFE配置
使用 afe_config_init() 获取默认配置并根据需求调整参数:
srmodel_list_t *models = esp_srmodel_init("model");
afe_config_t *afe_config = afe_config_init("MMNR", models, AFE_TYPE_SR, AFE_MODE_HIGH_PERF);
input_format:定义通道排列(如MMNR)。models:模型列表(如NS、VAD或WakeNet模型)。afe_type:AFE类型(如AFE_TYPE_SR表示语音识别场景)。afe_mode:性能模式(如AFE_MODE_HIGH_PERF表示高性能模式)。
步骤2:创建AFE实例
通过配置创建AFE实例:
// 获取句柄
esp_afe_sr_iface_t *afe_handle = esp_afe_handle_from_config(afe_config);
// 创建实例
esp_afe_sr_data_t *afe_data = afe_handle->create_from_config(afe_config);
步骤3:输入音频数据
将音频数据输入AFE进行处理。输入数据格式需与 input_format 匹配:
int feed_chunksize = afe_handle->get_feed_chunksize(afe_data);
int feed_nch = afe_handle->get_feed_channel_num(afe_data);
int16_t *feed_buff = (int16_t *) malloc(feed_chunksize * feed_nch * sizeof(int16_t));
afe_handle->feed(afe_data, feed_buff);
feed_chunksize:每帧输入的样本数。feed_nch:输入数据的通道数。feed_buff:通道交错的音频数据(16位有符号,16 kHz)。
步骤4:获取处理结果
获取处理后的单通道音频输出和检测状态:
afe_fetch_result_t *result = afe_handle->fetch(afe_data);
int16_t *processed_audio = result->data;
vad_state_t vad_state = result->vad_state;
wakenet_state_t wakeup_state = result->wakeup_state;
// if vad cache is exists, please attach the cache to the front of processed_audio to avoid data loss
if (result->vad_cache_size > 0) {
int16_t *vad_cache = result->vad_cache;
}
// get the processed audio with specified delay, default delay is 2000 ms
afe_fetch_result_t *result = afe_handle->fetch_with_delay(afe_data, 100 / portTICK_PERIOD_MS);
AFE 示例代码
#include "esp_afe_sr_iface.h"
#include "esp_afe_config.h"
static const esp_afe_sr_iface_t *afe_handle = NULL;
void feed_task(void *arg)
{
esp_afe_sr_data_t *afe_data = arg;
int audio_chunksize = afe_handle->get_feed_chunksize(afe_data);
int feed_channel = afe_handle->get_feed_channel_num(afe_data);
int16_t *buff = malloc(audio_chunksize * sizeof(int16_t) * feed_channel);
while (1) {
read_data_from_i2s_or_file(buff, ...); // read audio data from I2S or file
afe_handle->feed(afe_data, buff);
}
if (buff) {
free(buff);
buff = NULL;
}
vTaskDelete(NULL);
}
void fetch_task(void *arg)
{
esp_afe_sr_data_t *afe_data = arg;
int fetch_chunksize = afe_handle->get_fetch_chunksize(afe_data);
int16_t *buff = malloc(fetch_chunksize * sizeof(int16_t));
while (1) {
afe_fetch_result_t* res = afe_handle->fetch(afe_data);
if (!res || res->ret_value == ESP_FAIL) {
printf("fetch error!\n");
break;
}
... // process the results, e.g., res->data for AFE output, res->data_size for output data size, etc.
}
if (buff) {
free(buff);
buff = NULL;
}
if (afe_data) {
afe_handle->destroy(afe_data);
afe_data = NULL;
}
vTaskDelete(NULL);
}
void create_afe_task()
{
// 1. Initialize default configuration
afe_config_t *afe_config = afe_config_init("MNR", models, AFE_TYPE_SR, AFE_MODE_HIGH_PERF);
// 2. Create an AFE instance
afe_handle = esp_afe_handle_from_config(afe_config);
esp_afe_sr_data_t *afe_data = afe_handle->create_from_config(afe_config);
afe_config_free(afe_config);
// 3. Get feed frame length and allocate buffers
xTaskCreatePinnedToCore(&feed_task, "feed", 8 * 1024, (void*)afe_data, 5, NULL, 0);
xTaskCreatePinnedToCore(&fetch_task, "detect", 4 * 1024, (void*)afe_data, 5, NULL, 1);
}
资源占用
关于AFE的资源占用情况,请参阅 资源占用。