Touch 手写数字识别
Touch 原理与数据采集
Touch 原理
采用 ESP_Touch_Kit_Touchpad 作为 Touch 触摸板。该触摸板有 6*7 的 Touch 通道组成。

Touch 触控板实物图
当手指在 Touch 触摸板上移动时,会改变 Touch 通道的电容值,这时候我们就可以通过检测电容值的变化来判断手指的位置。
检测算法
因为硬件差异,各个通道触发的最大值和最小值不同,所以需要对各个通道的电容值进行归一化处理。通过手指在上面滑动,来记录各个通道的最大值和最小值。
在手指滑动的过程中,会有一路通道的电容值变化率最大,这时候再取相邻变化率最大的通道,可以获取到两条相邻的通道。
将两个通道的值进行差比和运算,可以获取到手指在该方向上的相对坐标(较两通道中心点的偏移量)。
通过上述步骤,可以获取到手指在两个方向上的相对坐标,从而可以确定手指的位置。
备注
需要设定合适的触发阈值,来判断手指是否在 Touch 触摸板上移动。
当检测到手指抬起,即可将绘制的数据进行保存。
数据采集
由于在实际的 Touch 触控板绘制数字时,其最终的图像并非类似于 MNIST 数据集中的手写数字,导致直接使用 MNIST 数据集训练的模型在实际应用中效果不佳。因此,需要采集实际的 Touch 触控板绘制数字的数据集,并进行训练。

基于 Touch 触控板绘制的真实数据集
备注
经过插值后的手写数据图像尺寸为 30x25
点击此处下载本示例中使用的数据集:touch_dataset.zip
模型训练与部署
模型搭建
基于 PyTorch 框架,搭建适用于 Touch 手写数字的网络模型,结构如下:
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.model = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Flatten(),
torch.nn.Linear(in_features=7 * 6 * 64, out_features=256),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(in_features=256, out_features=10),
torch.nn.Softmax(dim=1)
)
def forward(self, x):
output = self.model(x)
return output
模型训练
模型的训练过程包括数据集的加载与预处理,模型训练参数的设置,模型训练过程的监控与保存。
数据加载与预处理
将不同数字对应的图像分别放置在 dataset/extra 文件夹中,以数字作为文件夹名称,并使用 transforms.Compose 对图像进行预处理,包括灰度化、随机旋转平移与标准化。随后使用 ImageFolder 加载整个数据集,并按 8:2 的比例划分为训练集与测试集,最后通过 DataLoader 构建批量加载器以供后续模型训练和评估使用。
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, random_split
from torchvision import datasets, transforms
transform = transforms.Compose([
transforms.Grayscale(num_output_channels=1),
transforms.RandomAffine(degrees=10, translate=(0.1, 0.1)),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)),
])
dataset = datasets.ImageFolder(root='./dataset/extra', transform=transform)
train_size = int(0.8 * len(dataset))
test_size = len(dataset) - train_size
train_dataset, test_dataset = random_split(dataset, [train_size, test_size])
train_loader = DataLoader(dataset=train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=32, shuffle=False)
模型训练参数设定
模型训练参数包括学习率、优化器、损失函数等。实际训练过程中采用交叉熵作为损失函数,并使用 Adam 优化器进行模型参数的更新:
device = "cuda:0" if torch.cuda.is_available() else "cpu"
model = Net().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
模型训练与保存
设置训练轮数为 100 轮,并使用训练集和测试集分别进行训练和评估。训练过程中使用训练集进行模型参数的更新,并使用测试集进行模型性能的评估。训练结束后,将模型参数保存为 ./models/final_model.pth 文件。
def train_epoch(model, train_loader, criterion, optimizer, device):
model.train()
running_loss = 0.0
correct = 0
total = 0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
epoch_loss = running_loss / len(train_loader)
epoch_acc = 100 * correct / total
return epoch_loss, epoch_acc
def test_epoch(model, test_loader, criterion, device):
model.eval()
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
epoch_loss = running_loss / len(test_loader)
epoch_acc = 100 * correct / total
return epoch_loss, epoch_acc
num_epochs = 100
train_acc_array = []
test_acc_array = []
for epoch in range(num_epochs):
train_loss, train_acc = train_epoch(model, train_loader, criterion, optimizer, device)
test_loss, test_acc = test_epoch(model, test_loader, criterion, device)
print(f'Epoch [{epoch + 1}/{num_epochs}], '
f'Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}%, '
f'Test Loss: {test_loss:.4f}, Test Acc: {test_acc:.2f}%')
train_acc_array.append(train_acc)
test_acc_array.append(test_acc)
torch.save(model.state_dict(), './models/final_model.pth')
模型训练过程中,训练集与测试集的准确率变化曲线如下:
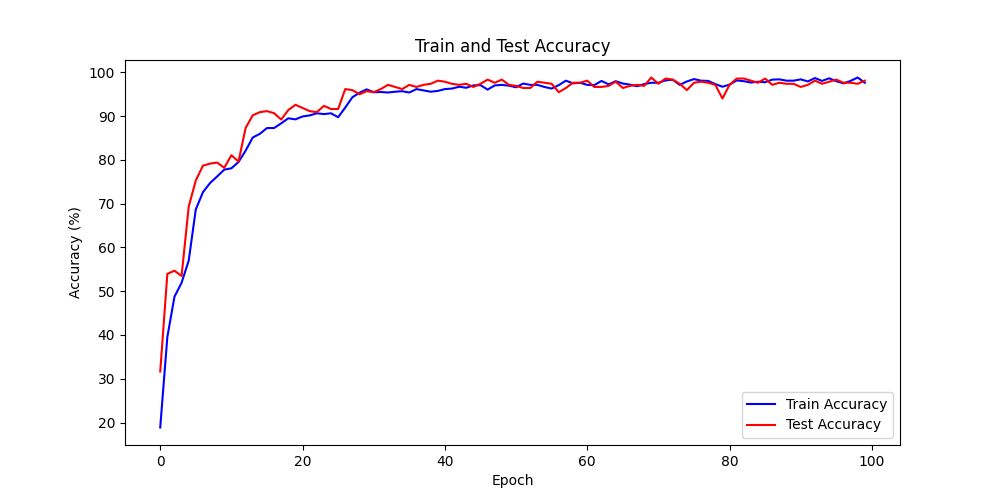
训练集与测试集的准确率变化曲线
模型部署
ESP-PPQ 环境配置
ESP-PPQ 是一种基于 ppq 的量化工具。请使用以下命令安装 ESP-PPQ:
pip uninstall ppq
pip install git+https://github.com/espressif/esp-ppq.git
模型量化与部署
参考 How to quantize model 实现对模型量化与导出。若需要导出适用于 ESP32P4 的模型,请将 TARGET 设置为 esp32p4。
import torch
from PIL import Image
from ppq.api import espdl_quantize_torch
from torch.utils.data import Dataset
from torch.utils.data import random_split
from torchvision import transforms, datasets
DEVICE = "cpu"
class FeatureOnlyDataset(Dataset):
def __init__(self, original_dataset):
self.features = []
for item in original_dataset:
self.features.append(item[0])
def __len__(self):
return len(self.features)
def __getitem__(self, idx):
return self.features[idx]
def collate_fn2(batch):
features = torch.stack(batch)
return features.to(DEVICE)
if __name__ == '__main__':
BATCH_SIZE = 32
INPUT_SHAPE = [1, 25, 30]
TARGET = "esp32s3"
NUM_OF_BITS = 8
ESPDL_MODEL_PATH = "./s3/touch_recognition.espdl"
transform = transforms.Compose([
transforms.Grayscale(num_output_channels=1),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)),
])
dataset = datasets.ImageFolder(root="../dataset/extra", transform=transform)
train_size = int(0.8 * len(dataset))
test_size = len(dataset) - train_size
train_dataset, test_dataset = random_split(dataset, [train_size, test_size])
image = Image.open("../dataset/extra/9/20250225_140331.png").convert('L')
input_tensor = transform(image).unsqueeze(0)
print(input_tensor)
feature_only_test_data = FeatureOnlyDataset(test_dataset)
testDataLoader = torch.utils.data.DataLoader(dataset=feature_only_test_data, batch_size=BATCH_SIZE, shuffle=False,
collate_fn=collate_fn2)
model = Net().to(DEVICE)
model.load_state_dict(torch.load("./final_model.pth", map_location=DEVICE))
model.eval()
quant_ppq_graph = espdl_quantize_torch(
model=model,
espdl_export_file=ESPDL_MODEL_PATH,
calib_dataloader=testDataLoader,
calib_steps=8,
input_shape=[1] + INPUT_SHAPE,
inputs=[input_tensor],
target=TARGET,
num_of_bits=NUM_OF_BITS,
device=DEVICE,
error_report=True,
skip_export=False,
export_test_values=True,
verbose=1,
dispatching_override=None
)
为了便于调试模型,ESP-DL 提供了在量化期间添加测试数据并在 PC 端查看推理结果的功能。在上述过程中,image 被加载至 espdl_quantize_torch 中被用于测试。在模型转换结束后,测试数据的推理结果将在以 *.info 为后缀的文件中保存:
test outputs value:
%23, shape: [1, 10], exponents: [0],
value: array([9.85415445e-34, 1.92874989e-22, 7.46892081e-43, 1.60381094e-28,
3.22134028e-27, 1.05306175e-20, 4.07960022e-41, 1.42516404e-21,
2.38026637e-26, 1.00000000e+00, 0.00000000e+00, 0.00000000e+00],
dtype=float32)
重要
在模型量化与部署过程中,请将 torch.utils.data.DataLoader 中的 shuffle 参数设置为 False。
端侧推理
参考 How to load test profile model 与 How to run model 实现模型的加载与推理。
需要注意的是,在本例中,Touch 驱动上报的按下与未按下的状态为 1 与 0,而模型的输入为标准化后的图像数据,因此需要对 Touch 驱动上报的数据进行预处理:
for (size_t i = 0; i < m_feature_size; i++) {
int8_t value = (input_data[i] == 0 ? -1 : 1);
quant_buffer[i] = dl::quantize<int8_t>((float)value, m_input_scale);
}
完整的项目工程请参考: ai/esp_dl/touchpad_digit_recognition