TTS 语音合成模型
乐鑫 TTS 语音合成模型是一个为嵌入式系统设计的轻量化语音合成系统,具有如下主要特性:
目前 仅支持中文
输入文本采用 UTF-8 编码
输出格式采用流输出,可减少延时
多音词发音自动识别
可调节合成语速
数字播报优化
自定义声音集(敬请期待)
简介
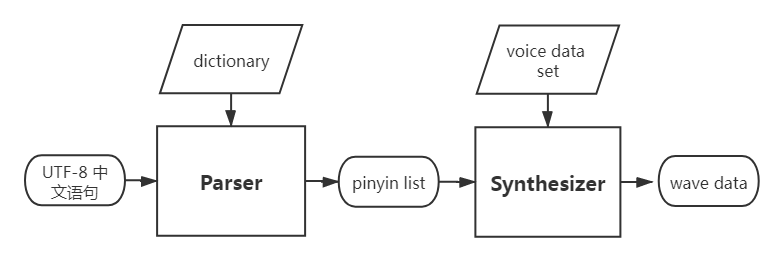
乐鑫 TTS 的当前版本基于拼接法,主要组成部分包括:
解析器 (Parser):根据字典与语法规则,将输入文本(采用 UTF-8 编码)转换为拼音列表。
合成器 (Synthesizer):根据解析器输出的拼音列表,结合预定义的声音集,合成波形文件。默认输出格式为:单声道,16 bit @ 16000Hz。
系统框图如下:
简单示例
esp-tts/samples/xiaoxin_speed1.wav (voice=xiaoxin, speed=1):欢迎使用乐鑫语音合成,支付宝收款 72.1 元,微信收款 643.12 元,扫码收款 5489.54 元
esp-tts/samples/S2_xiaole_speed2.wav (voice=xiaole, speed=2): 支付宝收款 1111.11 元
编程指南
#include "esp_tts.h"
#include "esp_tts_voice_female.h"
#include "esp_partition.h"
/*** 1. create esp tts handle ***/
// initial voice set from separate voice data partition
const esp_partition_t* part=esp_partition_find_first(ESP_PARTITION_TYPE_DATA, ESP_PARTITION_SUBTYPE_DATA_FAT, "voice_data");
if (part==0) printf("Couldn't find voice data partition!\n");
spi_flash_mmap_handle_t mmap;
uint16_t* voicedata;
esp_err_t err=esp_partition_mmap(part, 0, part->size, SPI_FLASH_MMAP_DATA, (const void**)&voicedata, &mmap);
esp_tts_voice_t *voice=esp_tts_voice_set_init(&esp_tts_voice_template, voicedata);
// 2. parse text and synthesis wave data
char *text="欢迎使用乐鑫语音合成";
if (esp_tts_parse_chinese(tts_handle, text)) { // parse text into pinyin list
int len[1]={0};
do {
short *data=esp_tts_stream_play(tts_handle, len, 4); // streaming synthesis
i2s_audio_play(data, len[0]*2, portMAX_DELAY); // i2s output
} while(len[0]>0);
i2s_zero_dma_buffer(0);
}
更多参考,请前往 esp-tts/esp_tts_chinese/include/esp_tts.h 查看 API 定义,或参考 ESP-Skainet 中 chinese_tts 示例.
资源消耗
有关本模型的资源消耗情况,请见 资源消耗。