TTS Speech Synthesis Model
Espressif TTS speech synthesis model is a lightweight speech synthesis system designed for embedded systems, with the following main features:
Currently Only supports Chinese language
Input text is encoded in UTF-8
Streaming output, which reduces latency
Polyphonic pronunciation
Adjustable output speech rate
Digital broadcasting optimization
Customized sound set (coming soon)
Overview
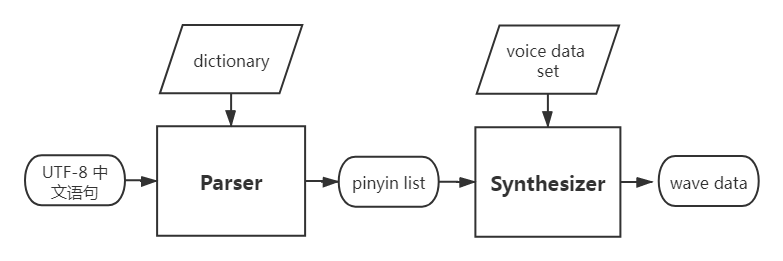
Using a concatenative method, the current version of TTS includes the following components:
Parser: converts Chinese text (encoded in UTF-8) to phonemes.
Synthesizer: generates wave raw data from the phonemes provided by the parser and the sound set. Default output format: mono, 16 bit @ 16000 Hz.
Workflow:
Examples
esp-tts/samples/xiaoxin_speed1.wav (voice=xiaoxin, speed=1): 欢迎使用乐鑫语音合成,支付宝收款 72.1 元,微信收款 643.12 元,扫码收款 5489.54 元
esp-tts/samples/S2_xiaole_speed2.wav (voice=xiaole, speed=2): 支付宝收款 1111.11 元
Programming Procedures
#include "esp_tts.h"
#include "esp_tts_voice_female.h"
#include "esp_partition.h"
/*** 1. create esp tts handle ***/
// initial voice set from separate voice data partition
const esp_partition_t* part=esp_partition_find_first(ESP_PARTITION_TYPE_DATA, ESP_PARTITION_SUBTYPE_DATA_FAT, "voice_data");
if (part==0) printf("Couldn't find voice data partition!\n");
spi_flash_mmap_handle_t mmap;
uint16_t* voicedata;
esp_err_t err=esp_partition_mmap(part, 0, part->size, SPI_FLASH_MMAP_DATA, (const void**)&voicedata, &mmap);
esp_tts_voice_t *voice=esp_tts_voice_set_init(&esp_tts_voice_template, voicedata);
// 2. parse text and synthesis wave data
char *text="欢迎使用乐鑫语音合成";
if (esp_tts_parse_chinese(tts_handle, text)) { // parse text into pinyin list
int len[1]={0};
do {
short *data=esp_tts_stream_play(tts_handle, len, 4); // streaming synthesis
i2s_audio_play(data, len[0]*2, portMAX_DELAY); // i2s output
} while(len[0]>0);
i2s_zero_dma_buffer(0);
}
See esp-tts/esp_tts_chinese/include/esp_tts.h for API reference and see the chinese_tts example in ESP-Skainet.
Resource Occupancy
For the resource occupancy for this model, see Resource Occupancy.