AI Inference
ESP-VISION provides on-device neural-network execution through espdl – Model Inference, which uses ESP-DL, and tflite – Model Inference, which uses TensorFlow Lite Micro for TensorFlow Lite .tflite models. The available APIs range from task-oriented helpers to general model execution, and model-specific preprocessing or post-processing can live in module bindings, helper code, or Python scripts depending on the model family.
Model Runtimes
ESP-DL and TFLite Micro are the current model runtime paths exposed by ESP-VISION. The espdl module works with .espdl files, and tflite.Model works with .tflite files. Model files are stored on board storage, such as /sdcard or /flash, and loaded at runtime. The API shape, quantization metadata, and input/output interpretation are defined by the selected runtime and model.
Model Files and Quantization
Models are usually exported or converted offline from a training framework before they are copied to board storage. On microcontrollers, quantized models are preferred because they reduce model size, activation memory, and arithmetic cost. Quantization maps floating-point tensor ranges onto integer values with scale and zero-point metadata; the exact metadata and file layout depend on the runtime and conversion toolchain.
Inference flow
A single inference call usually combines several stages: prepare input data, run the quantized network, and decode raw outputs into values the application can use:
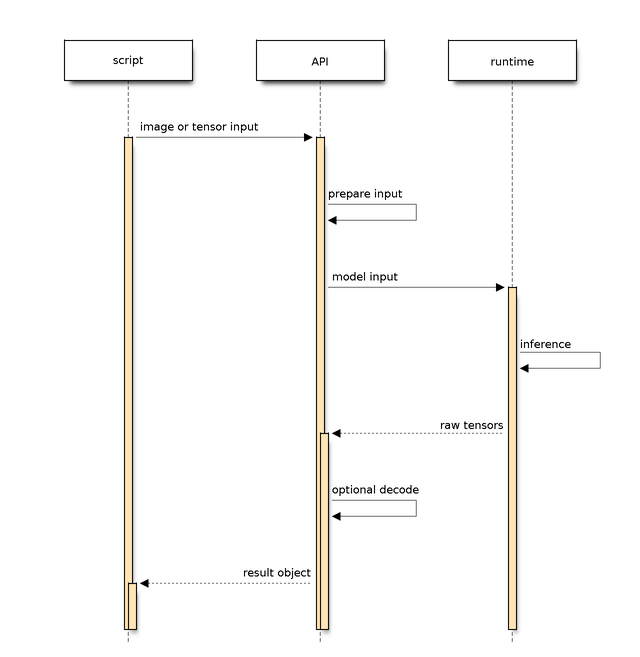
Pre-processing
Before inference the input data must match what the model was trained on:
Shape must match the model input tensor, including resolution and channel count for image models.
Color order and pixel format must match the training pipeline.
Normalization or quantization must use the scale, zero point, mean, standard deviation, or other transform expected by the model. Some APIs expose these as parameters, while examples may show them directly in Python.
Post-processing
Raw network outputs often need task-specific decoding before they are useful to an application:
Object detection (
espdl.ESPDet,espdl.YOLO11) produces candidate boxes with class scores. A confidencescorethreshold drops weak boxes and non-maximum suppression (nms) removes overlapping duplicates, leaving(x, y, w, h, score, category)tuples.YOLO11also caps results withtopk.Pose estimation (
espdl.YOLO11nPose) adds 17 COCO keypoints per detection.Classification (
espdl.ImageNetCls) applies an optionalsoftmaxand returns thetopk(label, score)pairs.Raw output decoding (
espdl.Model,tflite.Model) exposes model outputs before task decoding. Application code must unpack the tensor dtype, use the quantization metadata, and run model-specific steps such as anchor decode, sigmoid or softmax, NMS, top-k selection, and coordinate mapping.
Thresholds and result limits can often be tuned at runtime without reloading the model, which is useful when adapting to lighting, distance, or scene density.
Memory and performance
Models and their activation buffers are large and are allocated in PSRAM. Load a model once and reuse it across frames rather than recreating it per frame. Call deinit() (or drop the last reference) to free a model when you are done. Inference cost usually scales with input resolution and model size, so smaller models generally run at higher frame rates than full-size networks.